A graph from the FDA review of Paxlovid appears to substantiate the theory and anecdotes of viral resurgence. Here I offer my reconstruction of the methods used to produce the graph, and the opinion that there is a decent likelihood that this evidence is valid.1
Rebound
The Official Unglossed Totally Reckless Theory™ (OUTRT) for how Paxlovid could be creating a temporary pause, and then resurgence (“rebound”) of viral replication and symptoms in some number of recipients… may not have been so reckless after all.
Besides the anecdotes unearthed beforehand by Igor Chudov,2 the FDA Emergency Use Authorization review turns out to feature tangible evidence that accords with my “Paxlovid Viral Rebound” theory. This evidence was also unearthed by none-other-than Chudov, and he was kind enough to bring it to my attention a follow-up comment to Friday’s post - and so, all credit for the discovery of this possible medical fiasco continues to go to him. Again, here is his original post (and see my Part 1 for description of the theory).
And here is the astonishing evidence for apparent viral rebound after treatment with Paxlovid, constructed via PCR cycle count values during the trial that led to the drug’s EUA, and turned over by Pfizer in response to a semi-perfunctory FDA follow-up query:
Although the data used to construct this graph was provided to the FDA in order to assuage concerns over mutagenic viral resistance (escape) of the active molecule in Paxlovid, it nonetheless appears to air an entire closet’s-worth of dirty pharma laundry regarding the durability of improvement in viral load conferred by the standard 5-day course of this drug. So much so, that the copy-writer of the FDA review remarked:
Several subjects appeared to have a rebound in SARS-CoV-2 RNA levels around Day 10 or Day 14
No kidding. 3 patients seem to have gone from “0 RNA copies per mL” to nearly 1,000,000 or higher. That’s akin to a rebound from the locker room after the game ended. It seems like something that should have prompted the refs to blow a whistle or two.
But no whistles were blown. And so, learning that the border agent inspecting Pfizer’s car noted without further investigation that the back seat was half drenched in red liquid only shoulders us with the burden of parsing, retroactively, the likelihood that the liquid was blood or ketchup again (Kyle3). And this burden is substantial, given that neither the official trial publication nor the FDA review are precise with describing the methodology used to construct this graph. The answers to the following questions are thus both crucial and semi-indicipherable:
Who is in this sample (how many patients are in the graph, and was there some sort of built-in bias for patients that still had symptoms, or is it a more random, representative slice of reality)?
How reliable is the scale (how was “viral load” derived, and was testing consistent)?
And given 2, is this result actually so unusual (or is it within the normal range of noise from PCR tests derived from nasal swabs)?
Were there any linked regressions in symptoms among Paxlovid recipients, or a signal for same?
After follow-up, my best guess is that the answers to the above are:
97 random Paxlovid recipients.
Likely highly reliable and consistent.
At least four, and possibly eight, of the rebounders are truly unusual. However, co-treatment with monoclonal antibodies may be a confounder. (Edit, May 1: It seems safe not to worry about the monoclonal antibodies confounder at this point, given official acknowledgement of the Paxlovid rebound trend.)
The trial document implies that such outcome data exists, but was not published. This will be discussed further in a follow-up post.4
Read on to get into the weeds of how the first three conclusions were derived. A caveat which applies to the following report is that these details, again, were mostly inferred and pieced-together from what was available. Additionally, I may have simply missed some direct descriptions of the relevant methods in the trial and review documents, given the sprawling nature of both, which may provide a more accurate portrayal of events. Still, the following should provide an illuminating case-study on quantitative PCR and study interpretation for anyone who is interested.
Reminder: If you anticipate deriving value from this post, please drop a few coins in your fact-barista’s tip jar.
click button or visit https://ko-fi.com/unglossed
Who is in this sample?
The above graph was created to demonstrate that Paxlovid recipients with viral sequences that contained possible mutations to nsp5 (or “MPro,” the protease that breaks up most of the Orf1 polyprotein, as described in Part 1) or its target cleavage sites did not show signs of resistance to the drug. FDA representatives had asked Pfizer for whatever evidence was available that nsp5 mutants were not anti-Paxlovid resistant “escape” mutants, in other words.
In reply, Pfizer’s trial operators effectively constructed a post hoc cohort from within their already mind-trippy, nested three-stage set of trial participants: Everyone in the treatment or placebo groups who had nasal swab qPCR results with associated “viral load” values, 480 (not 490) of which underwent further sequencing (“NGS analysis”). The raw(-ish) “viral load” and sequence data for these participants was handed over to the FDA.
The FDA effectively constructed a second post hoc cohort from “everyone in the sample,” first by limiting to those who had “viral load” values on both Day 1 and Day 5 (852 out of an unknown value for “everyone”5), and then by limiting to those with sequence data on the same (2166).
97 of this post post hoc cohort of 216 were from the eventual ~1,039 Paxlovid-finishing trial participants; 13 of whom (the red lines in Figure 2) turned out to have the suspected escape mutants at the accepted sensitivity threshold, the other 84 of which didn’t. The FDA’s Figure 2 is likely to have been constructed out of the “viral load” data for these 97. The point of the graph, again, is just to show that said 13 mutant-havers (red) weren’t very “escape-y” compared to the 84 non-havers (grey). It turned out that mutant-having had nothing to do with resistance to the drug; some recipients from both sets experienced upswings in “viral load” after Day 5.
Which is exactly why Figure 2 corroborates my wild theory (which has nothing to do with mutations to or selection upon the virus; again, see Part 1).
Thus, we seem to have the answer to “who,” and can evaluate if there were any biases driving the results.
The only apparent bias is for “availability of sequence results on Day 1 and 5.” This may indicate that only American subjects were included in the FDA’s post post hoc cohort, given logistical considerations around shipping to whichever lab which performed sequencing. And among the resulting 97 Paxlovid recipients, it is unclear how many were also in the “co-treatment with monoclonal antibodies” group - but the overall number for this group for the whole trial was only 70 for both treatment and control (6.2% of all participants),7 and this is presumably even lower if these samples were from subjects enrolled before the Interim Analysis. Naturally, all trial participants were all considered “at-risk” of the virus, but this same diagnostic bias applies to real-world use of the drug. And almost no one in the graph was likely hospitalized for severe disease, since that outcome was so rare in the treatment group according to the official trial results (which I am only just now reading; it turns out our little protease inhibitor really was “overwhelmingly effective”8).
Again, little of this is explicitly described in the review document, which reads as if the author was partly confused about the methodology behind Figure 2. My reason for assigning 97 to the number on the graph is that a “N(o)” value for “Has potential resistance acquiring sequence (RAS)” implies that the grey lines were, in fact, sequenced (even though what the graph is showing is “viral load” as determined merely by qPCR cycle count, which corresponds to a larger virtual treatment cohort of 428). My reason for assuming all grey lines correspond to Paxlovid-recipients is that the FDA-supplied caption reads “Paxlovid treated subjects,” not “trial participants” (including placebo).
These biases should be arbitrary as far as an analysis of viral rebound goes: i.e., they shouldn’t do anything to skew the plotted recipients toward outliers who had a certain outcome (such as return of symptoms) after Day 5 (only a handful appear to drop off before Day 14, and so most who make it to the chart to begin with stay through until the end, apparently regardless of full recovery). However, they also may not exclude outliers with significant confounders - namely, the unlabeled and non-numbered “treated with monoclonal antibodies” set.
Finally, it’s worth noting that Figure 2 (per this interpretation) excludes what should be our actual control group - the placebo group’s “viral load” values, even though these were included in the data turned over to the FDA.
This gap in the data means we will only be able to compare the results in Figure 2 with results for “non-treated humans” derived from different diagnostic labs that may translate poorly to the assay used here, and one study which I believe involved the same assay.
How reliable is the scale?
Although Pfizer’s “post hoc cohort” is presumably selected due to having had their samples sequenced, the graph is plotting “viral load,” not sequence values.
I have been scare-quoting viral load because the values plotted in Figure 2 (and used for other analysis in the trial) were derived from PCR nasal swabs. So how did Pfizer measure the “RNA copies” in a “mL” of a nasal swab? Well, they didn’t. The swabs were subjected to PCR amplification, and the number of cycles required to acquire a positive test was converted into “RNA copies/mL” via math. But all that was really known was the cycle count.
If “viral load” is really just a mathematical translation of cycle count, then what matters (to an outside reader, who wants to glean something about reality; whereas to Pfizer and the FDA this is all apparently just “biological performance art”) is 1) whether a consistent test site was used to produce the counts, and 2) whether the mathematically-derived scale is similar to other uses, as inferred from whatever secondary threshold was used to calibrate said scale (if not, then our expectations should be adjusted in turn).
My interpretation of the trial text leads me to conclude that these results were derived from a custom assay at the University of Washington which should robustly correspond to “normal” thresholds.9 In fact, it was probably an exemplar, or at least not too shabby an example, of the “ideal” quantitative PCR viral load assay as described by Mara Aspinall:10
How do we judge what level of viral load is infectious? Every infectious disease has a minimum quantity of virus necessary for an infection to take hold. This varies by virus and by an individual’s immune competency. The Lab gold standard to determine this is to infect a cell culture with SARS-CoV2 virus. These experiments indicate that anywhere from 1,000 [“3”] to 100,000 [“5”] viral copies per milliliter are required to create a viable COVID-19 infection. […] [T]his threshold is consistent with clinical experience. Very few patients with moderate to severe disease sample below this level. […]
Across all samples run on the same protocol, Ct will accurately reflect relative viral load differences sample to sample. Generating comparability beyond that requires each lab to publish what is called a “Standard Curve” for each test protocol it performs. This translates “apples and oranges” Ct counts to more comparable viral loads expressed in terms of number of viral copies per milliliter. This is done by taking a sample of known viral concentration (available commercially) and running a series of 10x dilutions on the same protocol and recording the resulted Ct with each known level of viral load for that specific test, run in that particular way, by that particular lab.
Aspinall, Mara.
As a demonstration, we plotted Ct versus viral load for a more-or-less random group of eight assays reported in the academic literature.
In a well-calibrated quantitative assay, in other words, “4” corresponds to a cell culture infectivity cut-off which is generally assumed to translate to clinical significance. But in practice, higher values (mathematically derived from lower cycle counts) will still correspond to higher likelihood of a true-positive for active infection. Based on the calibration values published in a paper by Berg, et al., the University of Washington assay employing Abbott RealTime PCR seems to provide good resolution on both scales: It includes a robust demonstration of the same cut-off for their “4” value, and reports excellent consistency in the range above and below.11
Using the published calibration for the University assay, we can plot this threshold as a margin and annotate the raw cycle count values behind the derived viral load, landing ourselves on firmer ground:
https://www.fda.gov/media/155194/download, Fig 2 (annotated). The “Infectivity threshold” is represented as a range to reflect inherent uncertainty in the biology of qPCR viral load quantification and cross-comparison with other assays.
Using thresholds that will offer a near-comparison to another assay in the next segment, our tentatively notable “Paxlovid-rebounders” are thus as follows:
Still, note that our assumed identification of the assay used for Figure 2 is intrinsically hazardous. If the University assay wasn’t the one actually used for Figure 2, the values for “4” could turn out to be semi-meaningless. To quote Aspinall again (emphasis added):12
The FDA has never before allowed reporting of a quantitative result from a qualitative viral test without requiring the calibrated standard curve in viral copies/ml on which the yes/no answer is based, and therefore allowing cross-assay comparison. 13
Is this result actually so unusual?
Since the FDA did not publish the longitudinal “viral load” values for the placebo group, we must compare these results to assays that may have different or less accurate thresholds, and would also differ in sample collection methods.
Additionally, most of the canonical, published “viral load” kinetics for SARS-CoV-2 take several patients and average them together, forming smooth curves. What we are interested in, is how often an individual can be expected to test negative, then positive, as determined by the “4” or “6” thresholds.
One such glimpse is offered by the recent infection challenge paper by Killingly, et al.14 Again, these results are using a different assay and may not translate well to the University of Washington results. Also, the subjects in this study were “healthy volunteers,” as opposed to the at-risk patients in the Paxlovid trial.
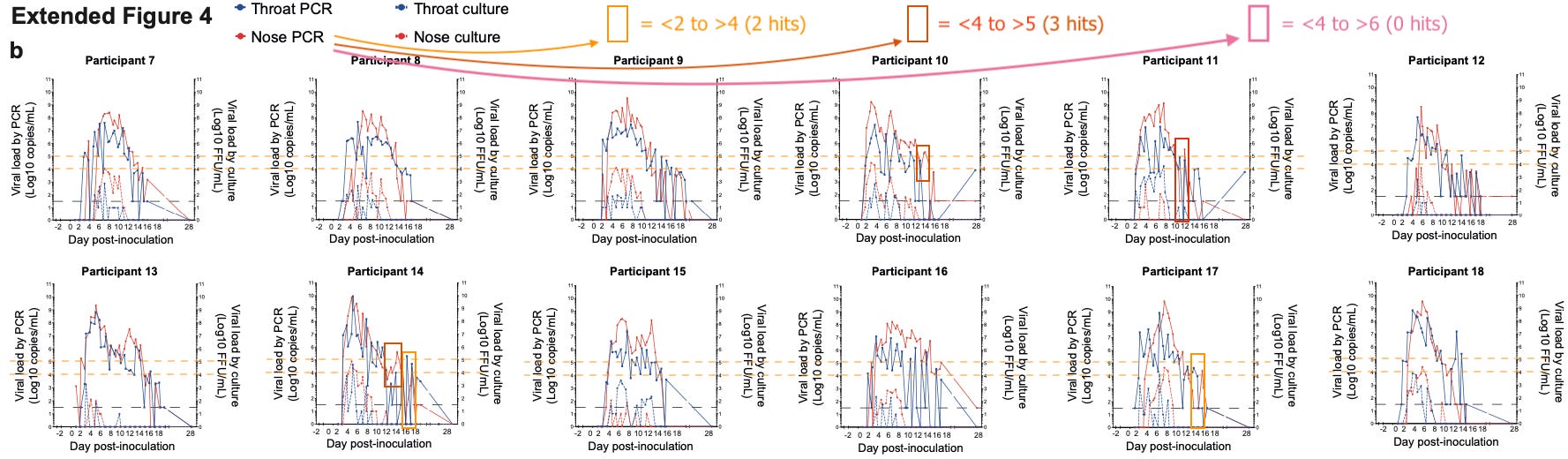
Still, it is notable (and not entirely surprising) that whereas there is some tendency to bounce between under and over “4” in the latter days of infection (as lower values are more prone to false negatives and positives), none of the subjects jump from under “4” (10,000) to over “6” (1,000,000) in that assay:
Killingly, et al. Extended Fig. 4 (annotated; click to enlarge).
In the Paxlovid trial, 4 recipients went even further than this not-met-by-our-“control” benchmark, and jumped from 100 to 1,000,000 in the assay’s values. Meanwhile, the “smaller” jumps (note that I used a different threshold for this one, which was prepared earlier) in the “4 and below” range seem less unusual.
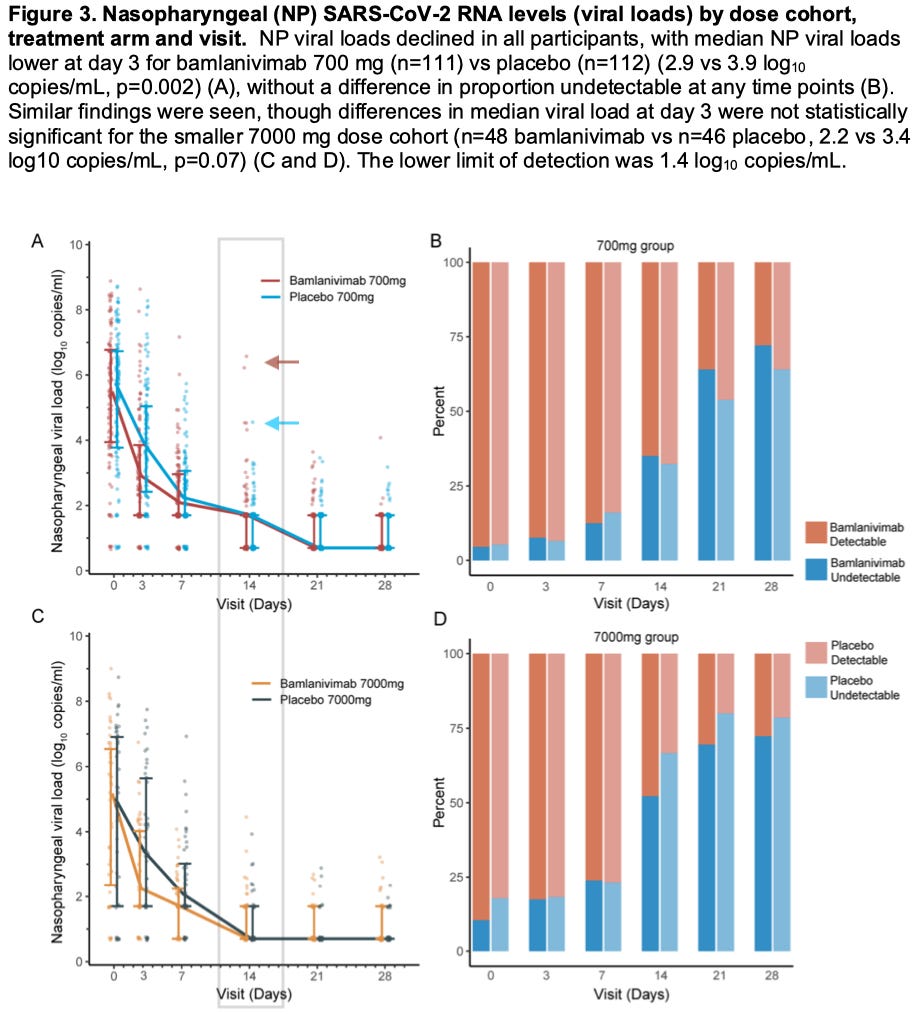
A second paper, by Chew, et al., seems to provide a benchmark for the results the University of Washington assay specifically is likely to provide for a non-treated “control” group.15 In this, 158 control patients are compared vs monoclonal antibody treatment in the trial for “Bamlanivimab.” Dry-ice-perserved swabs were sent to the University of Washington for processing on the assay described by Berg, et al., and results were sent back to the trial and plotted on various figures. In this one, longitudinal comparison between values is not provided, but it seems clear that only one of controls scores above “4” on Day 14 (blue arrow):
Chew, et al. Fig. 3 (annotated).
However, two of the “Babiddybamblab”-treated patients do score above “6” on Day 14 (brown arrow). These may or may not be “rebounders,” since the plots are not connected between one day or the next. Still, these high Day 14 values in the treatment group demonstrate the obvious possibility that monoclonal antibody treatment drives this type of lingering high “viral load” (low cycle count) in general.
In Conclusion
There is now evidence potentially corroborating the anecdotes and Official Unglossed Totally Reckless Theory. The evidence is striking, but not conclusive; especially given the lingering lack of clarity on whether the University of Washington assay was used or not.
At this point, as regards the crime of viral resurgence according to the OUTRT, I would say it is still probably too early to put out a “warrant” for Paxlovid’s arrest. But if the suspect turns up knocking at your door, you might want to consider not letting him in.
Edit, May 1: The original version of the synopsis referred to a “so-so” likelihood, rather than a “decent” likelihood. Future readers are probably not in need of any precautions about making too much of this evidence, and so I have chosen a less equivocal phrasing.
The initial version of this post included an incorrect interpretation of the not-given “everyone” value based on my attempted incorporation of the “490” number, which simply seems to be a typo on the FDA’s part.
With some glaring exceptions in which factors actually were associated with risk of severe outcomes for the placebo group; more on which in a future post. Ironically, one of the mutation-havers may have been hospitalized per Table 11, but it is not clear if this patient met the sequence specificity threshold).
But this turns out to require still more best-guess-work. From the Supplementary Appendix of the cryptic, official trial document:
(Hammond, et al. Supplementary Appendix, p10.) Viral Load Assessment
Quantitative viral load was generated using a validated Abbott RealTime Quantitative SARS- CoV-2 assay at the University of Washington Medicine Clinical Virology Laboratory. The RT-PCR assay was intended for the quantitative detection of nucleic acid from SARS-CoV-2 in nasopharyngeal or nasal swabs by detecting the RdRp and nucleocapsid (N) genes using the Abbott m2000 System. Total RNA for viral load analysis was extracted from swabs using the Roche MagnaPure LC automated platform.
So which was it? The Abbott at the University of Washington, or the Roche at who-knows-where [or is this me misunderstanding whether more than one assay is even being described]? I’m inclined to believe that the more detailed-sounding first method applies for the longitudinal results in our figure, whereas the second method was employed for the separate purpose of randomizing trial subjects by initial viral load (qPCR cycle count). (It is because the trial used qPCR for two separate ends that two methods are given, in my interpretation.)
However, an internet search for “Abbott quantitative PCR” eventually leads to a study which describes robust validation of the test’s quantitative application, and includes five of the same authors as Degli-Angeli, et al.:
As implied by the title, the University of Washington assay has been calibrated according to correlation with viral culture, which brings it in line with the “ideal” quantitative assay described by Aspinall. From the “highlights” section (emphasis added):
Modified FDA EUA qualitative RealTime SARS-CoV-2 assay into a quantitative LDT.
Analytical and clinical performance performed using nasopharyngeal swabs.
High linearity (R2 = 0.992) and high inter/intra-assay reproducibility seen across dynamic range.
Lower limit of detection was determined as 1.90 log10 [~79] copies/mL.
Ct < 29, corresponding to > 4.2 log10 [15,849] copies/mL, correlated with ability to culture in Vero cells.
Fantastic post! Thank you for directing your attention and competence to this. I believe that we are just getting started really looking at paxlovid.
If I recall correctly, paxlovid was tested on unvaccinated people. If vaccinated people are disproportionally getting viral resurgence, this could be due to the following:
- The 5 day PAUSE button that is called Paxlovid, leads to mostly satisfactory results in UNvaccinated people, whose immune system can mount vigorous response during those 5 days, leading to only 20% viral resurgence
- If vaccinated people, due to immune system damage/tolerance to the spike antigen, are unable to create durable immune response during the same 5 day pause, it could explain resurgence in them.
In addition, it may be that Omicron, despite appearing mild, takes more time to clear and a five day PAUSE is not enough. As you or maybe Modern Discontent alluded to, it may be that the protease inhibitor needs to be given for longer (but hopefully not forever as you mentioned)
In addition, it may be that paxlovid trial was rigged, and resurgences were somehow masked by trial protocol.
Want to add my name to the Paxlovid rebound list. Tested positive PCR and antigen, took 5 day regimen of Paxlovid, symptom free by day six, tested negative, two days later, all symptoms returned, tested positive, still positive after ten days, but mostly symptom free.















Fantastic post! Thank you for directing your attention and competence to this. I believe that we are just getting started really looking at paxlovid.
If I recall correctly, paxlovid was tested on unvaccinated people. If vaccinated people are disproportionally getting viral resurgence, this could be due to the following:
- The 5 day PAUSE button that is called Paxlovid, leads to mostly satisfactory results in UNvaccinated people, whose immune system can mount vigorous response during those 5 days, leading to only 20% viral resurgence
- If vaccinated people, due to immune system damage/tolerance to the spike antigen, are unable to create durable immune response during the same 5 day pause, it could explain resurgence in them.
In addition, it may be that Omicron, despite appearing mild, takes more time to clear and a five day PAUSE is not enough. As you or maybe Modern Discontent alluded to, it may be that the protease inhibitor needs to be given for longer (but hopefully not forever as you mentioned)
In addition, it may be that paxlovid trial was rigged, and resurgences were somehow masked by trial protocol.
More from Twitter (using my alt account as I am blocked for misinformation, pending appeal)
People are getting interested in our paxlovid stuff, without mentioning us of course but whatever
https://twitter.com/EnemyInAState/status/1516588639270092809
https://twitter.com/walidgellad/status/1516040963239653388
https://twitter.com/JFdonoghue1033/status/1515811645515259908 (look at the replies to this one)
https://twitter.com/SteveJoffe/status/1516136976944095247
https://www.coronaheadsup.com/health/treatment/paxlovid/paxlovid-covid-19-infections-rebounding-a-few-days-after-treatment/
https://twitter.com/baby2thfairy/status/1516192113842655243
GOOD ONE: https://twitter.com/TaraL3056/status/1516132283991957514
https://twitter.com/SlightlyUnripe/status/1516566835042287617
https://twitter.com/WoollerEmma/status/1516359610956931080
https://twitter.com/poblematisch/status/1516285346379710469
Apr 21:
https://www.thailandmedical.news/news/urgent-studies-needed-on-paxlovid-does-it-only-help-alleviate-symptoms-and-suppress-viral-load-for-a-while-but-does-not-help-in-total-viral-clearance
https://twitter.com/JeremyLeven1/status/1517264324644982784 <-- he may be a doctor
Want to add my name to the Paxlovid rebound list. Tested positive PCR and antigen, took 5 day regimen of Paxlovid, symptom free by day six, tested negative, two days later, all symptoms returned, tested positive, still positive after ten days, but mostly symptom free.