The SARS-CoV-2 spike protein has been reported as having proven prionogenic abilities.
It really doesn’t.
Correction, October 4, 2022: Interpretation of the PLAAC “black underlines” in the initial version of this post was misleading; references to the black underlines has been mostly removed. Full change-log in the footnotes.1
This weekend, I decided it was time to offer my readers a take on the “Spike protein and prions” controversy. Is this just another facet of the “Alzheimer’s virus panic,” or is there something here? For newer readers, this post will be a complement to a prior entry, which discussed how science is coming to understand amyloids as part of the brain’s innate immune system:
But since I am not strong in “protein science,” the first thing I needed to do was get a handle on the question:
What are prions?
Prion Town
“Prions” and prion-forming proteins: A ten minute crash-course.
I. Prion protein vs. “prions”
“Prions” are an inaccurate term typically used to refer to the mis-folded, aggregated form of a ubiquitous, rapidly recycled, and likely essential human protein, the “Prion protein.”
Prion (PRNP) protein isoforms:
PrPC: Normal, healthy form, non-aggregating. Many animal species have their own form of this protein.
PrPSc: Misfolded forms, aggregating. The “information” of just how individual PrPSc isoforms are shaped is sometimes transmitted to other PrPCs belonging to the same species or sometimes to other species, at least in lab conditions.
PrPSc. Neural tissue in scrapie-infected mouse. “Sc” is for scrapie; but is generally applied to misfolded forms of prion protein that cause diseases.
But not all species of prion proteins can transmit their misfolded / amyloid form to the healthy form.2
“Prion protein” is thus to “prions” as Gizmo is to the gremlins in a once-popular movie: The cute, delicate creature that will spawn something tough-skinned and chaos-spreading, if conditions are met.
Just some cute, visual aid-type imagery. Don’t bring your RNA next to this guy if you know what’s best.
II. The World of Prion proteins
Human Prion protein is expressed by varying amounts in different types of nervous tissue, as well as immune cells, and to a lesser extent in basically every tissue type. Your body is using this protein to do stuff. Maybe, like, brain stuff or immune stuff. We don’t really know.
Other animals have their own prion proteins. They are “conserved” in structure: There is not much variation compared to each other or to ours. So, animal bodies are using this protein to do stuff too (however, the regulatory machinery in the DNA surrounding the Prion protein gene is extremely varied between species).3
Finally, fungi have their own prion proteins. They are similar to ours, but different. Prion proteins used by S. cerevisiae — brewer’s yeast — have helped us build an understanding of what is “essential” to the “prion-forming” quality of animal prion protein, leading to the formation of computer algorithms that can look for “prion”-like sequences in other proteins.
François Jaques: Peasants Enjoying Beer at Pub in Fribourg. “Thank you for making beer and for your prion insights, S. cerevisiae.”
III. “Prions” vs. “Amyloid”
The reason “prion” is an inaccurate term is because the definition becomes either incomplete — “misfolded proteins” — or circular — “misfolded Prion protein.”
All “prions” (misfolded prion protein aggregates) are amyloid; but not all amyloids (misfolded proteins) are “prions.” Only misfolded prion proteins are “prions.”
“Prions” cannot just emerge from vague, generic “misfolding-ness.”
They basically only involve prion protein. But unknown prion-forming domains may exist in other proteins, and suspected “potential prion-forming” or “prion-like” regions do appear in other parts of the proteome.
IV. “Prion-forming” vs. “amyloid-prone” domains
Amyloids first: The prevailing, cool-kid theory of how eukaryotes (nucleus-having organisms) put amyloid together is referred to as the “short stretch hypothesis.” Amyloid-prone proteins have a generic, “velcro-strip”-like chain of 5 to 20 amino acids somewhere in the entirety of the molecule.4 These stretches are enriched in residues N (Asparagine, Asn) or Q (Glutamine, Gln). For reference, here is my (normally gorgeous) bitmap of the genetic code organized by the 2nd letter of every codon, marred with the names of each amino acid:
N and Q are akin to lego blocks with a T shape — with a simple, “amide” side chain, they can easily hook onto (main chain-) parallel “amino” acid main chains.
Models for N and Q from wikipedia (annotated). The side-chain (left arrow) amides (CONH2’s) allow for generic cross-attachment with other main chains (not shown) to this main chain (right arrow). Lots of other side chains can bind non-cognate residues, but would presumably be too promiscuous (cross-reactive) in a disordered state. Just spit-balling on that one.
These Ns and Q-rich stretches claw to each-other, and the rest of the formerly ordered protein can just dangle off in either direction, and there you have your amyloid:
Sabate, R. et al. (2015.) Fig. 1. “Nucleation” occurs when the no-longer structured stretch of one protein disorders and binds with the stretch in another, resulting in aggregation. (Note that this specific illustration is meant to double as a “prion-like” sequence model; since after all all oranges (prions) are fruit (amyloids).)
The catch here is that the bacteria proteome does not have many of these domains.5 Since bacteria rely heavily on amyloid for forming biofilms and other stuff, how do they get by? Well, because lots of proteins can form amyloid; and lots of conditions can expand the capacity or tendancy of amyloid-transition. So the short stretch hypothesis is not a biological axiom. It does, however, seem more central in eukaryotic amyloid. If you are looking for amyloidogenic proteins in an animal, you will look for short stretches of N and Q.
Prion proteins feature a more complex iteration of this molecular logic, which is not found in bacteria at all. In the amyloid-forming sequences of fungal and animal prion proteins, N and Q are still important, but there is also a curious abundance of inert G’s (Glycine, Gly).
Prion-forming domains are thus a very unique biological motif, varying from semi-regular Ns and Qs sandwiching an abundance of Gs to heavier N and Q repeats with less regular Gs; S and Y are also distinctive markers.7
The prion-forming domain is the sine qua non of prion proteins:
If this domain is taken away from prion proteins, misfolded proteins can no longer transfer their state to normal molecules.8 It may act as both the "lock" and "key" of the prion protein: Some species of prion proteins that are not transmission-compatible became compatible when the prion-formind domain of one was spliced onto the superstructure of the other.9
V. Conclusion: Proteins can contain amyloid- or prion-ogenic domains
They are not the same thing, in terms of composition or function. Though they both can end up forming amyloids, fibrils, etc.
Unlike amyloid-prone domains, there is no substitute for a prion-forming domain. You need it for a “prion” — a protein that can transmit and receive a disordered state. Take this domain out of a prion protein, and it won’t transmit or receive disorder any more.
Computer algorithms can score a given protein for likelihood of containing either one. We are concerned today with longer, N, Q, S, Y, and G-rich prion-forming domains.
A high score for a prion-forming domain does not prove an ability to interact with bona fide prion protein. However, the algorithm has a somewhat well-understood molecular basis, and fungal prion-forming domains can be transferred to other proteins without loss of function. So identified prion-forming domains are not proven, but “presumed” guilty.
We already know the spike protein is amyloidogenic. So the seperate question of whether it is prionogenic is simply a matter of whether it has a prion-forming domain or not.
Does the Spike protein contain a prion-forming domain?!?!
No.
Like, lol, no no.
The following paper, of course, appears to claim otherwise, and largely upon the basis of this paper, the prion-forming nature of the Spike protein has been somewhat widely hyped:10
The key difference here is the distinction between a true prion-forming domain, and a so-called “prion-like domain.” They haven’t got the same meaning.
Tetz, Tetz used the “Prion-Like Amino Acid Composition” tool, PLAAC, which is freely available online.11 Let’s get very vaguely familiar with the tool:
PLAAC is built around two-dozen or so known or suspected fungal prion proteins. The false-positive rate for (novel) PLAAC-identified prion-forming regions isn’t really known, because not much work has been done to validate positives. But “at least one” of 19 prospective novel S. cerevisiae prions was validated.12
Fungal prion-forming domains that don’t obey the algorithm have been found.13 Since PLAAC doesn’t know how to predict “prion-forming” regions that disobey the algorithm, it simply misses any that might exist in the scanned protein (false negatives). Oh well.
PLAAC can scan a single protein for prion-forming-domain-having, or scan a “whole-proteome” for below-cutoff patterns that resemble a true prion-forming domain. For example, Kim, et al. found that 1.2% of human proteins contain “possible PrLDs,” with “PrLD” scores >0.14 These might be vulnerable to mutations that would activate true prion-domain-having, but they should not be considered prion-domain-having proteins. They are referred to as "Prion-like domains," but this does not mean that they are like in function.
Here is literal, human Prion protein:
PLAAC for human PrPC. Top: 1 means the algorithm is “sure” this is a prion-forming domain, marked in the sequence (bottom) with red text. Middle: Scoring for folding-ness with FoldIndex. Below 0 (grey shade) regions are predicted to be intrinsically disordered, and are marked in the sequence with black underline.
The known prion-forming domain has been correctly marked in the red text at the bottom, corresponding to the high red zone in the top graph.
Another uptick in red, circa residues 160-175, could by the “rules” of the PLAAC tool be called a “prion-like domain.” But it isn’t a prion-forming domain; it doesn’t look like one (no G-repeats); it won’t act like one. The algorithm thinks there is a small chance it could be one; that means it isn’t one (low-probability results like this are relevant when searching through an entire proteome; they aren’t intrinsically meaningful in discrete proteins; more discussion below). The Prion protein only has one prion-forming domain, and the red text identifies which domain that is.
Here, for a curveball, is the SARS-CoV-2 N Protein:
A disordered region (black underline) in the N-terminal (beginning) of the molecule briefly scores high in the algorithm (red text), thanks to interspersed N and Q, and some Gs. While this region might be too short to function as a true prion-forming-domain, the lack of order and high N and Q content are suggestive of amyloidogenic potential in general. More on the implications in Pt 2.
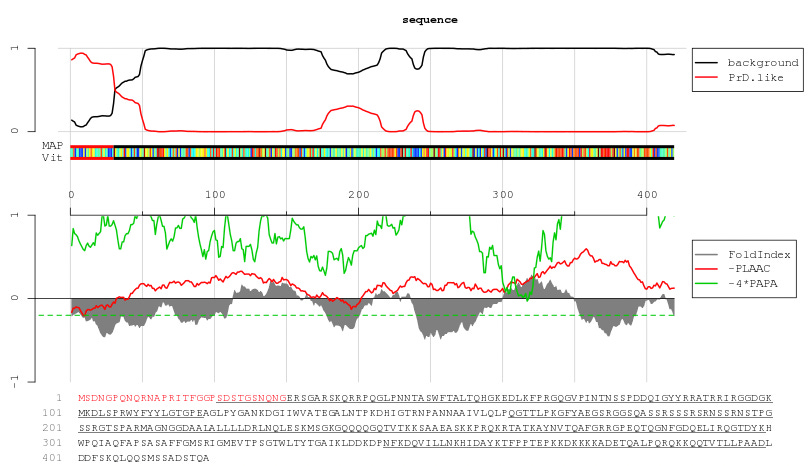
And now, drumroll, the deadly, super-powered, apocalypse-ushering (Wuhan-model) spike protein:
No red text. PLAAC does not find the spike protein to contain a prion-forming domain. It has found one region of the Receptor Binding Domain, near the 500 mark, that, like above, could be called “prion-like” (the tiny uptick in red in the top graph) — but as discussed above the use of “like” here is mere semantics. Almost none of the spike protein scores as intrinsically disordered (grey shade).15
However, the “prion-like” region may still be instrumental in the amyloidogenic effects of the S1 subunit on plasma as observed by Resia Pretorius and co.16 Or it may not. And moreover, these amyloidogenic effects could be another of those ubiquitous features of microbial molecules and the innate immune system that we simply haven't studied enough yet.
But since the Omicron siblings have removed several of the Ns and Qs in this region, the relevance of this domain to amyloid clotting can presumably now be tested in vitro.
Modified version of my modified version of the Omicron mutation map by Andrew Rambaut. Mutations in the alleged “Prion-like” domain of the spike protein. Green are shared by both BA.1 and BA.2. (BA.4/5 revert to 493Q.)
Results:
Wuhan-era spike (still included in all mRNA vaccines, extinct in the wild):
Amyloidogenic: Yes, based on in vivo and in vitro effects on patient / healthy plasma.
Prionogenic: No. Lacks a functional prion-forming domain or anything close to it.
Omicron-era spike:
Amyloidogenic: ?
Prionogenic: No.
Here, as one last counter-example, is a random-year version of the H1N1 flu spike protein (HA):
And so, to wrap up, when Tetz, Tetz find that PLAAC scores the spike protein as having a “prion-like domain” it simply means that if you were looking at a lot of proteins, you could list this among many that have a-priori potential for being a prion-forming domain; in this case, the real-life potential is still zero. So they have used the tool incorrectly (in that they were not sorting through a whole proteome). From the paper presenting the tool:
In addition, we compute a score LLR (for log-likelihood ratio) that is otherwise identical to COREscore, but without the requirement that the sequence falls entirely within the PrLD state of the HMM parse. Because LLR does not impose a hard cutoff, it can be useful when doing exploratory whole-proteome analyses, e.g. on the overall distribution of (near) PrLDs.17
From Tetz, Tetz:
In this study, we performed the first detailed evaluation of PrDs in the spike protein of SARS-CoV-2 and compared them to PrDs from other human-pathogenic β-CoVs. We also analyzed PrDs in the spike protein of the variants of concern (VOC) B.1.617.2 (Delta) and B.1.1.529 (Omicron), variants of interest (VOI) and variants being monitored (VBM), such as B.1.1.7 (Alpha), B.1.351 (Beta), P.1 (Gamma), B.1.427 (Epsilon), B.1.617.1 (Kappa) and P.2 (Zeta)
[Thus, they are only looking at one type of protein, not the whole proteome.]
We used a 3.0 log-likelihood ratio (LLR) cutoff, which reflects the maximum sum of per-residue log-likelihood ratios for any subsequence of length Lcore that falls partially or entirely within the prion-like domain state in the HMM Viterbi parse within a provided sequence18
That’s math-speak for “we didn’t use the tool correctly.”
Saying the spike protein is “prion-like” is like saying a rattle is “rattlesnake-like.”
In Pt 2:
Synergy between spike and N in neurological attack?
Guanine-Rich RNA (like in Covid vaccines) and Prions
Corrected reference to W as one of the prion-ogenic residues (it should have been Y).
Corrected upload for PLAAC results for human Prion protein and corresponding text description (I used a version with spaces in the aa sequence, which PLAAC interprets as unspecified residues).
Corrected spelling of “guanine,” thanks to reader spellcheck.
Oct 4:
The range of prion-forming domains:
Corrected description of PLAAC algorithm training base. Rather than using just the 4 iconic S. cerevisiae proteins, the prion-forming domain from 28 (presumed?) fungal prion proteins is now used.
Added example of Sup35 prion domain, and broadened description of the prion-forming domain to accommodate a “motif” with a range of models, rather than a single, “specific design.”
The big mess over the black underlines:
Significant rewrite of the PLAAC results to correct the interpretations of the middle graphs and sequence annotations regarding the fold score. The initial interpretation took the PLAAC plot (red line) in the middle graph to correspond to folding / disorder and to the “black underlines.” The correct interpretation is that only the fold-score (grey shade) corresponds to these qualities. The initial version of this post thus incorrectly described the potential / “prion-like” area of the Wuhan spike code to match the black underlined stretch; they are adjacent.
Correspondingly, the PLAAC results for the N protein were re-uploaded without my inaccurate markup highlighting where the PLAAC plot dips in the second graph. The text description was altered to describe disordered regions as corresponding to black underline exclusively.
Correspondingly, my description of the PLAAC results for the spike protein was modified to more accurately report the two (potential) disordered regions (grey shade; black underline), with specifics in footnote 15.
Overall, the lack of any sequence markup in PLAAC for “prion-like” makes discussion of this terminology in single-protein results completely misleading. Of course, that was the whole conclusion in the original version of this post: “Prion-like” is not meaningful in results for single proteins. But since that is how Tetz, Tetz arrived at their conclusions; it is necessary to run-through the process they used in both an example protein (human Prion protein; the “second and third” humps) and the spike. This is an awkward task. At present I am still not happy with the modified text.


















{kind=link}


Thank you, Brian. I always look forward to your posts.
Have you shared this with Jessica Rose?